CLARION模型:内隐与外显技能学习的整合(2)
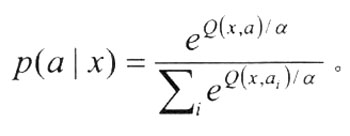 |
 |
 |
3.2 CLARION模型的算法
底层内隐学习使用分布式表征加工。在有正确输入/输出映射时,可用直接反向传播学习算法,否则使用强化学习。总之,可使用Q学习反向传播算法(Q-learning-backpropagation algorithm, QBP)发展内隐技能。顶层外显学习可用局域符号表征加工。个体基于假设检验进行一次性学习(one-shot learning),可使用规则抽取精化算法(rule-extraction- refinement algorithm,RER)抽取外显规则。它能动态获得表征,并可按需修改,这反映了技能学习的动态特征。因此,个体既可以用自上而下的方式,在内隐学习中使用顶层获得的外显知识,也可以用自下而上的方式,在外显学习中使用底层获得的内隐知识。
3.2.1 底层算法描述
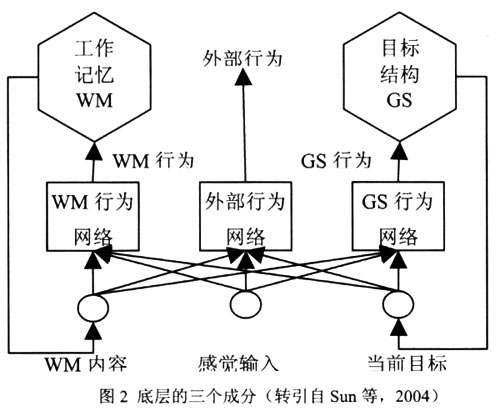
如图2所示,底层的输入包括三组:感觉输入(sensory input)、工作记忆项目(working memory items)、目标堆栈的顶项(the top item of the goal stack)。它们各有不同维度,每个维度都有各自的值。
, 百拇医药
底层的输出包括三组行为选项:工作记忆的设置/重置、目标堆栈的推进/弹出、外部行为。他们由不同网络计算。每个网络基于Q值(对行为质量的评价)计算行为。Q(x, a)表示状态x下行为a的适宜程度。通过Boltzmann 分布,由Q值可计算出将要执行的某一行为的概率:
其中α表示决策加工的随机度。
Q学习算法是一个强化学习算法,此时Q(x, a)也表示从当前状态x可得到的最大贴现累计强化
3.2.2 顶层算法描述
顶层外显知识为一种命题规则形式。Sun等使用规则抽取精化算法描述自下而上的学习加工,其算法描述为:(1)更新统计量;(2)更新规则(3条标准):[10]
①抽取:若结果成功符合当前标准,且没有匹配状态和所采取行为的现成规则,则抽取新规则:状态→行为。该规则加入规则网络;
, http://www.100md.com
②专化(Specialization):若结果不符合当前标准,则通过专化修正所有匹配规则:从规则网络中去除这些匹配规则,并在规则网络中加入修正的规则版本;
③概化(generalization):若结果成功符合当前标准,则概化这些匹配规则:从规则网络中去除这些匹配规则,并在规则网络中加入概化的规则。
3.2.3 CLARION模型双层结构的全局算法
尽管在CLARION中既有自下而上的加工,也有自上而下的加工,但Sun等更强调自下而上的学习[10]。其全局性算法描述如下[16]:(1)观察当前状态x;(2)在底层计算每个行为(ais)的“值”,它们与状态x相联结:Q(x, a1), Q(x, a2), . . . , Q(x, an) ;(3)基于状态x(由底层来)和顶层现有行为规则,找出顶层所有可能的行为(b1, b2, . . . , bm) ;(4)基于底层ais与顶层bjs的合并,随机选择一个适当的行为;(5)执行行为a,观察下一状态y与可能存在的强化r;(6)基于反馈,按照QBP算法更新底层;(7)用RER算法更新顶层;(8)返回第一步。
, http://www.100md.com
上述第4步通过合并两个层次的结果,决定采取那个行为。如果顶层表明行为a激活值为va,底层显示行为a激活值为qa,则最终的结果为w1×va+w2×qa。基于该加权和,用Boltzmann分布从可能行为中决定选择哪一行为。
4 CLARION模型对经典实验的模拟
Sun等用CLARION对系列反应时(serial reaction time, SRT)任务、动态控制(dynamic control, DC)任务及另外两个高级认知任务进行了模拟[10]。在模拟中,底层和顶层分别使用QBP和RER算法。其做法大致如下:
(1)外显指导条件(告知被试如何做)采用顶层给定知识的外显编码来模拟;
(2)口语报告条件(要求被试在任务操作期间说出他们的思考过程)通过变换那些可促进更多顶层活动的参数来模拟;
, 百拇医药
(3)外显搜索条件(明确要求被试寻找刺激的规则)通过更多的顶层规则的学习来模拟。
模型中参数设置为:固定参数设置依据先前研究;网络权重在-0.01~0.01间随机初始化;Q值贴现率设为0.95;随机决策参数设为0.01;两层的合并权重设为w1=0.2,w2=0.8;密度参数设为1/50。以下是Sun等对一些经典实验的模拟,限于篇幅,我们只介绍匹配结果。
4.1 对系列反应时任务的模拟
对Lewicki等实验的模拟匹配结果发现,模型可给出一个下降的错误率曲线,类似于Lewicki实验中的反应时曲线[18]。Sun等尝试了两种方法,将模拟的错误率转换为反应时。线性转换后,模型的结果与人类的数据拟合很好。但转折到随机序列后,模型反应时变化很大,而人类的反应时受到的影响相对轻微。幂函数转换后,减少了模型的预测力,但获得了转折点后的更好匹配。该模型能成功匹配人类数据,应归功于底层的反向传播网络,顶层在该任务中的作用并不显著。
, 百拇医药
对Curran等实验的模拟匹配结果发现,使用线性转换将错误率转换为反应时,结果符合人类数据的特征[21]。幂函数转换效果更好。与Cleeremans的模拟相比,CLARION更接近人类被试,而且误差均方更小。两个模型的主要区别在于,CLARION中含有自下而上的学习。CLARION在模拟中得到了两层间的交互效应:(1)外显指导效应;(2)意识程度效应;(3)协同效应(指导语和意识程度的提高都有助于提高成绩);(4)双任务效应(第二任务的干扰引起的指导语和意识效应的消失)。
4.2 对动态控制任务的模拟
对Stanley等实验的模拟与人类被试数据拟合很好,误差均方仅为0.19。模拟显示了口语报告效应,口语报告组的成绩与控制组相比有极显著提高;较之控制组,记忆训练组和简单规则组的成绩都有极显著的提高,这些都与人类数据相同[22]。对Berry等实验的模拟匹配,也得到较好的拟合结果[23]。
, 百拇医药 总体上说,动态控制任务的模拟与人类数据都证实了口语报告效应和外显指导效应。两种效应都指向了顶层的积极一端。顶层增强后,无论通过口语报告还是给予外显指导,成绩都有所提高。这显示了顶层外显加工和底层内隐加工的协同效应。
4.3 对高级认知技能任务的模拟
Sun等还以河内塔(Tower of Hanoi)和雷区导航(minefield navigation)作为高级认知技能学习任务,模拟相关数据[12]。结果发现,在人类数据及其模拟中,口语报告条件产生了比标准条件更好的成绩,而标准条件又产生了比双任务条件更好的成绩。这说明,顶层的外显加工有助于提高学习效果(协同效应)。
相对于系列反应时和动态控制任务而言,河内塔和雷区导航任务更复杂,有更多的输入维度、输入类型,涉及复杂的输入-输出映射,并且通常没有唯一正解。这些任务反映了现实世界的特征,且比其他任务涉及更多真实世界的技能学习。
[ 上 页 ] [ 下 页 ], http://www.100md.com(杜建政 李 明)