原始数据函数变换对GM(1,1)模型精度的影响
作者:潘家英 闵祥云
单位:马鞍山钢铁总公司卫生防疫站, 安徽 马鞍山 243003
关键词:灰色模型;统计预测;变量变换
疾病控制杂志990217
【指示性摘要】 对原始数据进行不同形式的函数变换会引起GM(1,1)模型预测精度的变化。
【中图分类号】 R195.1 R311 【文献标识码】 A 【文章编号】 1008-6013(1999)02-0110-02
Variation in the accuracy of the model of GM(1,1) caused by the functional transformation for initial data
, http://www.100md.com
PAN Jia-ying, MIN Xiang-yun.
Station of Disease Prevention and Control of Steel Company of Maanshan, Maanshan 243303, China
【Directory abstract】 The functional transformation for initial data may change the accuracy of the model of GM(1,1) in predretion.
【Key words】 grey model; statistical predicton; functional transformation
近年来,在卫生领域各项指标值的预测中,GM(1,1)灰色一维模型已被广泛采用[1]。其预测精度与模型的选择及原始数据的预处理有一定的关系,一般提高GM(1,1)模型预测精度的方法有残差修补、等维灰色递补等,实践证明这些方法对提高模型预测精度是比较有效的。但不少文献试图用原始数据本身的函数某种变换增加原始数据的光滑度来提高预测精度,本文认为这种变换不具普遍意义。
, 百拇医药
1 数据列的对数函数、幂函数变换与模型的精度[2]
以某市性传播疾病发病率为例,x(k)={30.46,57.84,86.07,135.55,178.91},用原始数据直接建立预测模型为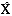 (k+1)1=141.0699e0.3596 k-110.6099;经对数函数、幂函数变换(原始数据开4次方再取自然对数)后预测模型为(k+1)2=66.6748 e0.0211 k+65.3248。两模型还原后的预测值见表1。
(k+1)1=141.0699e0.3596 k-110.6099;经对数函数、幂函数变换(原始数据开4次方再取自然对数)后预测模型为(k+1)2=66.6748 e0.0211 k+65.3248。两模型还原后的预测值见表1。
表1 x(k)原始数据列几种模型的比较 x(k)(k+1)1
, http://www.100md.com
误差1(%)(k+1)2
误差2(%)(k+1)3
误差3(%)
30.46
30.46
0.0
30.46
0.0
30.46
, 百拇医药
0.0
57.84
60.09
3.9
54.77
5.3
57.40
0.7
86.07
86.95
1.0
77.87
9.5
, http://www.100md.com
81.16
5.7
135.55
124.58
8.1
114.26
15.7
118.18
12.8
178.91
178.51
0.2
173.52
, http://www.100md.com
3.0
177.70
0.7
2 数据列的自然对数变换与模型精度的关系
仍以x(k)序列为例,x(k)序列经自然对数转换后预测模型为(k+1)3=47.8909 e0.08203 k-44.4745。经反自然对数取值,理论预测值见表1。其中误差(%)的计算方法是,实际值序列各值减去相应理论值序列各值,其差的绝对值除以实际值序列备值再乘以100%,并四舍五入精确一位小数。
3 数据列平移变换与模型精度的关系[3]
, http://www.100md.com
以某文“灰色模型法十年尘肺发病预测”为例,原文发病数序列x(t)={1,6,1,1,0,2,1,1,1,8,1,2,1,2},对x(t)不经变换其预测模型为(k+1)4=-490.6669e-0.00404 k+491.6669,原始数据水平上移29后其预测模型为(k+1)5=(1+78.83)×e0.016 k-78.83。两模型还原后理论预测值见表2。
表2 市属企业历年尘肺发病实际值与两种模型预测值 年份
1976
1977
1978
, 百拇医药
1979
1980
1981
1982
1983
1984
1985
1986
1987
1988
1989
1990
发病例数
, http://www.100md.com
1
6
1
1
0
2
0
1
1
1
8
1
2
1
, http://www.100md.com
2(k+1)4
1
2
2
2
1
2
2
2
2
2
2
, 百拇医药
2
2
2
2(k+1)5
1
2
2
2
2
2
2
2
, 百拇医药
2
2
2
2
2
2
2
4 讨论
有文献认为,对原始数据进行光滑处理会提高模型预测精度。本文经实例验证后认为,经数据列的某种函数变换未必能提高模型的精度。至少对于递增数据列,经对数函数幂函数变换以及自然对数转换不能有效改善预测模型的精度。相反对于量级较大的数据列,经还原后可能造成更大的误差,所以应慎用此方法建立GM(1,1)模型。从表1不难看出,(k+1)2和(k+1)3所得的理论值与(k+1)1所得的理论值类似,其平均相对误差分别为2.64%,6.7%,3.98%,变换后的模型与未经变换的模型所得的理论值无显著性差别,经后验差检验模型均符合要求;至于平移变换法没有还原误差扩大现象,但也未见得能提高GM(1,1) 模型对原始数据列的预测精度。直接用原始数据建立的模型与x(t)序列上移29所得模型还原后的预测值基本相同,这里且不去用后验差分析这两种模型的精度等级,但就两模型的预测值而言,基本是一致的。
, 百拇医药
由此可知,精心挑选模型、提高预测精度,不能着眼于原始数据的函数变换,而要从误差本身去挖掘有用信息,建立残差修补模型,迭加到原模型上,直接修正残差,从而达到准确预测的目的。此外,要充分利用信息,有时只有增加1个新信息数据,就可大大提高预测值的可靠性。如“某市性传播疾病灰色模型预测”,按当时发病率(到1995年末)数据模型精度很可靠,但预测值与报告发病率有一定差距,若将1996、1997两年发病率(222.94/10万,254.92/10万)加到x(k)原始数列中,预测1997、1998年的发病率分别为273.12/10万,351.25/10万。这种模型的预测值更逼近未来报告发病率[1]。
作者简介:潘家英,女,36岁,主管医师
参考文献
[1] 邓聚龙.灰色系统基本方法.武汉:华中理工大学出版社,1992,96~101.
[2] 闵祥云,姚为玲.某市性传播疾病流行趋势灰色系统模型预测.安徽预防医学,1997,3(1):17.
[3] 汪亚照,谢 萍.灰色模型法十年尘肺发病预测.安徽预防医学,1997,3(3):71.
收稿日期 1998-10-06, 百拇医药
单位:马鞍山钢铁总公司卫生防疫站, 安徽 马鞍山 243003
关键词:灰色模型;统计预测;变量变换
疾病控制杂志990217
【指示性摘要】 对原始数据进行不同形式的函数变换会引起GM(1,1)模型预测精度的变化。
【中图分类号】 R195.1 R311 【文献标识码】 A 【文章编号】 1008-6013(1999)02-0110-02
Variation in the accuracy of the model of GM(1,1) caused by the functional transformation for initial data
, http://www.100md.com
PAN Jia-ying, MIN Xiang-yun.
Station of Disease Prevention and Control of Steel Company of Maanshan, Maanshan 243303, China
【Directory abstract】 The functional transformation for initial data may change the accuracy of the model of GM(1,1) in predretion.
【Key words】 grey model; statistical predicton; functional transformation
近年来,在卫生领域各项指标值的预测中,GM(1,1)灰色一维模型已被广泛采用[1]。其预测精度与模型的选择及原始数据的预处理有一定的关系,一般提高GM(1,1)模型预测精度的方法有残差修补、等维灰色递补等,实践证明这些方法对提高模型预测精度是比较有效的。但不少文献试图用原始数据本身的函数某种变换增加原始数据的光滑度来提高预测精度,本文认为这种变换不具普遍意义。
, 百拇医药
1 数据列的对数函数、幂函数变换与模型的精度[2]
以某市性传播疾病发病率为例,x(k)={30.46,57.84,86.07,135.55,178.91},用原始数据直接建立预测模型为
(k+1)1=141.0699e0.3596 k-110.6099;经对数函数、幂函数变换(原始数据开4次方再取自然对数)后预测模型为(k+1)2=66.6748 e0.0211 k+65.3248。两模型还原后的预测值见表1。表1 x(k)原始数据列几种模型的比较 x(k)
(k+1)1, http://www.100md.com
误差1(%)
(k+1)2误差2(%)
(k+1)3误差3(%)
30.46
30.46
0.0
30.46
0.0
30.46
, 百拇医药
0.0
57.84
60.09
3.9
54.77
5.3
57.40
0.7
86.07
86.95
1.0
77.87
9.5
, http://www.100md.com
81.16
5.7
135.55
124.58
8.1
114.26
15.7
118.18
12.8
178.91
178.51
0.2
173.52
, http://www.100md.com
3.0
177.70
0.7
2 数据列的自然对数变换与模型精度的关系
仍以x(k)序列为例,x(k)序列经自然对数转换后预测模型为
(k+1)3=47.8909 e0.08203 k-44.4745。经反自然对数取值,理论预测值见表1。其中误差(%)的计算方法是,实际值序列各值减去相应理论值序列各值,其差的绝对值除以实际值序列备值再乘以100%,并四舍五入精确一位小数。3 数据列平移变换与模型精度的关系[3]
, http://www.100md.com
以某文“灰色模型法十年尘肺发病预测”为例,原文发病数序列x(t)={1,6,1,1,0,2,1,1,1,8,1,2,1,2},对x(t)不经变换其预测模型为
(k+1)4=-490.6669e-0.00404 k+491.6669,原始数据水平上移29后其预测模型为(k+1)5=(1+78.83)×e0.016 k-78.83。两模型还原后理论预测值见表2。表2 市属企业历年尘肺发病实际值与两种模型预测值 年份
1976
1977
1978
, 百拇医药
1979
1980
1981
1982
1983
1984
1985
1986
1987
1988
1989
1990
发病例数
, http://www.100md.com
1
6
1
1
0
2
0
1
1
1
8
1
2
1
, http://www.100md.com
2
(k+1)41
2
2
2
1
2
2
2
2
2
2
, 百拇医药
2
2
2
2
(k+1)51
2
2
2
2
2
2
2
, 百拇医药
2
2
2
2
2
2
2
4 讨论
有文献认为,对原始数据进行光滑处理会提高模型预测精度。本文经实例验证后认为,经数据列的某种函数变换未必能提高模型的精度。至少对于递增数据列,经对数函数幂函数变换以及自然对数转换不能有效改善预测模型的精度。相反对于量级较大的数据列,经还原后可能造成更大的误差,所以应慎用此方法建立GM(1,1)模型。从表1不难看出,
(k+1)2和(k+1)3所得的理论值与(k+1)1所得的理论值类似,其平均相对误差分别为2.64%,6.7%,3.98%,变换后的模型与未经变换的模型所得的理论值无显著性差别,经后验差检验模型均符合要求;至于平移变换法没有还原误差扩大现象,但也未见得能提高GM(1,1) 模型对原始数据列的预测精度。直接用原始数据建立的模型与x(t)序列上移29所得模型还原后的预测值基本相同,这里且不去用后验差分析这两种模型的精度等级,但就两模型的预测值而言,基本是一致的。, 百拇医药
由此可知,精心挑选模型、提高预测精度,不能着眼于原始数据的函数变换,而要从误差本身去挖掘有用信息,建立残差修补模型,迭加到原模型上,直接修正残差,从而达到准确预测的目的。此外,要充分利用信息,有时只有增加1个新信息数据,就可大大提高预测值的可靠性。如“某市性传播疾病灰色模型预测”,按当时发病率(到1995年末)数据模型精度很可靠,但预测值与报告发病率有一定差距,若将1996、1997两年发病率(222.94/10万,254.92/10万)加到x(k)原始数列中,预测1997、1998年的发病率分别为273.12/10万,351.25/10万。这种模型的预测值更逼近未来报告发病率[1]。
作者简介:潘家英,女,36岁,主管医师
参考文献
[1] 邓聚龙.灰色系统基本方法.武汉:华中理工大学出版社,1992,96~101.
[2] 闵祥云,姚为玲.某市性传播疾病流行趋势灰色系统模型预测.安徽预防医学,1997,3(1):17.
[3] 汪亚照,谢 萍.灰色模型法十年尘肺发病预测.安徽预防医学,1997,3(3):71.
收稿日期 1998-10-06, 百拇医药