数据挖掘在医学上的应用
作者:丁祥武 杨莹
单位:丁祥武 中南民族学院计算机科学系 武汉 430074 ;杨莹 湖北省钟祥市人民医院信息科
关键词:数据挖掘;序列模式;关联规则;特征规则;分类规则;医学应用
郧阳医学院学报990312中国图书资料分类法分类号 R-37
数据挖掘(Data Mining)即数据库中的知识发现KDD(knowledge discovery in databases)是从大型数据库中提取人们感兴趣的知识,这些知识是隐藏的、事先未知的、潜在有用的信息,挖掘的知识表现为概念、规则、规律、模式等形式[1]。数据挖掘为大型数据集的利用提供了有效工具。
数据挖掘起源于条码技术和大容量存储技术的使用,这样的环境使存储、处理大型的客户交易数据成为可能。随着计算机应用的日益普及,计算机在医学上的应用也越来越多。用计算机存储病案在医院已经比较普遍,而且各医院收集的数据又进一步汇总。如湖北省内县市级医院都用统一的医疗信息管理系统 SAS 来管理病案,这些数据又进一步汇总到省卫生厅,各省的病案数据进一步汇总。这样汇总的数据是相当庞大的,而且都是病人的真实数据,从这样的数据集中运用各种数据挖掘技术了解各种疾病之间的相互关系、各种疾病的发展规律,总结各种治疗方案的治疗效果,以及对疾病的诊断、治疗和医学研究都是非常有价值的。所以数据挖掘技术在医学上的应用是非常有潜力的。
, 百拇医药
数据挖掘发现的典型知识有序列模式、关联规则、特征规则、分类规则和聚类分析等。采用不同的技术可发现不同类型的知识。本文主要介绍挖掘序列模式、关联规则、特征规则和分类规则技术在医学上的应用。
1 序列模式及其在医学上的应用
给定一个交易数据库D,每条交易记录包含进行该交易的客户标识(Customer ID)、交易时间(Time)和在该交易中购买的项目(Items)。数据项集(Itemset)是数据项的非空集合,序列(Sequence)是数据项集的有序集。
设sa=A1,A2,…,Ak,sb=B1,B2,…,Bn是两个序列,如果存在整数1≤i12…k≤n使A1 Bi1,A2Bi2,…,AkBik,则称sa是sb的子序列,或称sb包含sa。例如<{3},{4,5},{8}>是<{3,8},{9},{4,5,6},{8}>的子序列,但<{3},{5}>与{3,5}>互不包含。
Bi1,A2Bi2,…,AkBik,则称sa是sb的子序列,或称sb包含sa。例如<{3},{4,5},{8}>是<{3,8},{9},{4,5,6},{8}>的子序列,但<{3},{5}>与{3,5}>互不包含。
, http://www.100md.com
在一个序列集合中,如果一个序列不包含在其它任何序列中,则称这个序列为最大序列。例如在{{3},{5},{3,5}}中,两个序列都是最大序列。
一个客户在一段时间内进行的所有交易可看作一个序列:s=〈itemset(T1),itemset(T2),…,itemset(Tn)〉,其中itemset(Ti)表示交易Ti采购的项目集,序列中的元素是按交易时间排序的,这样一个序列叫这个客户的客户序列。
如果一个序列s包含在一个客户的客户序列中,则称这个客户支持序列s。在一个交易数据库中,一个序列的支持度是支持这个序列的客户数占全部交易客户数的比例。
对一个交易数据库D,挖掘序列模式的任务就是在D中找出所有最大序列,这些序列满足用户指定的最小支持度,这样的一个序列叫一个序列模式。具有最小支持度的序列叫频繁序列。
, http://www.100md.com
在交易数据库D中挖掘序列模式是先将D转化为客户序列库Q,然后利用文[1,2]中介绍的方法,通过对Q多趟扫描找出各个长度的频繁序列,序列的长度指序列包含项的个数。例如对表1、2,如果用户指定的最小支持度为25%(有两位客户支持),则挖掘的序列模式有s1=<{30},{90}>和s2=<{30},{40,70}>。
表1 客户交易库D(已按客户号和交易时间排序) 客户号
交易时间
数据项
1
1999-02-20
30
1
, 百拇医药
199-02-25
90
2
1999-02-10
10,20
2
1999-02-15
30
2
1999-02-20
40,60,70
3
1999-02-25
, http://www.100md.com
30,50,70
4
1999-02-22
30
4
1999-02-28
40,70
4
1999-03-02
90
5
1999-02-10
90
, 百拇医药
如果在医院将就诊病人每次的病症输入到数据库中,组成一个庞大的数据库,对这个数据库进行一些必要的预处理,比如选取一类病情,然后利用挖掘序列模式的算法,挖掘满足支持度限制的序列模式,就可以发现一些病情的发展模式。
这种序列模式在医学上有许多作用,比如:
(1)确定某些疾病的发展模式,在治疗上可以根据病人的病史,预测病情发展趋势,从而有针对性地预防某些疾病的发生。
(2)给病人一些实际数据的说明,使病人高度重视某些疾病,防止病情进一步发展。
(3)如对某些治疗方案,收集治疗对象病情变化,每个病人的变化情况构成一个序列,在这样的序列库上挖掘序列模式,可以找出某些治疗方案的治疗效果。
(4)如果在数据库中记录时间信息,利用相应方法挖掘带时间约束的序列模式,可以进一步确定病情发展的时间情况或治疗效果的时间情况。
, 百拇医药
表2 表1对应的客户序列数据库Q 客户号
客户序列
1
<{30}{90}>
2
<{10,20},{30},{40,60,70}>
3
<{30,50,70}>
4
<{30},{40,70},{90}>
5
<{90}>
, 百拇医药
2 关联规则在医学上的应用
假设I={i1,i2,…,im}是项的集合。给定一个客户交易库D,每条交易T包含客户标识、交易时间和在该交易中购买的项目三个域。
如果对于I的一个子集X和D中的一条交易T有XT(文中有时简单用T表示在交易T中购买的项目集),则说交易T包含项集X,或交易T支持项集X。
一条关联规则是具有如下形式的蕴涵式X Y,其中X
Y,其中X I,YI,X∩Y=
I,YI,X∩Y=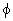 ,同时有两个阀值c、s分别表示该规则的可信度和支持度,可信度c表示支持X∪Y的交易在支持X的交易中所占的比例,而支持度s是支持X∪Y的交易在整个交易库中所占的比例。
,同时有两个阀值c、s分别表示该规则的可信度和支持度,可信度c表示支持X∪Y的交易在支持X的交易中所占的比例,而支持度s是支持X∪Y的交易在整个交易库中所占的比例。
, http://www.100md.com
在交易数据库D中挖掘关联规则的任务就是在D中找出所有满足用户指定最小支持度(min-support)和最小可信度(min-confidence)限制的关联规则。
一项集X的支持度是支持X的交易在整个交易库所占的比例。
在交易库D中挖掘关联规则可分解为下列两个子问题[3~4]:
(1)在D中找出所有的频繁项集,即支持不小于用户指定最小支持度的项集;
(2)应用频繁项集产生关联规则得到频繁项集之后,用它们确定关联规则是非常直接的,如果X是一个频繁项集,取X的非空子集α计算support(X)/support(α),如果其值≥c,则αX-α就是满足最小支持度和最小可信度限制的关联规则,其中α叫规则的头部。进一步考察信趣度interest=(C-T)/max{C,T}可筛选出真正有趣的规则,T为支持该规则头部的交易数与支持规则的交易数的比值。
, http://www.100md.com
找频繁集的过程[3~4]与前面找频繁序列的过程类似,也是通过多趟扫描交易库确定各个长度的频繁项集,项集的长度指的项集所包含项的个数。例如对表3所示的交易库,如果设s=60%(至少有两条交易支持),长度为2和3的频繁项集L2={{10,30},{20,30},{20,50},{30,50}},L3={{20,30,50}},如果设可信度c=70%,对频繁项集{10,30},1030满足最小可信度限制,而3010的可信度为2/3=66.6%,不满足最小可信度限制。进一步如果设最小兴趣度=85%,由于1030的兴趣度只有(100%-66.6%)/100%=33.4%,因而不是有趣规则。表3 客户交易库客 户号
, 百拇医药
交易时间
数据项
1
1999-03-18
10,30,40
2
1999-04-30
20,30,50
3
1999-05-15
10,20,30,50
4
, 百拇医药 1999-06-12
20,50
关联规则(Association rules)是最先提出的挖掘知识形式,也是数据挖掘的主要对象,主要应用于支持决策之中,只从Agrawal R[2]等在文中提出以来,就引起了数据库研究及其应用界的极大关注,其模型也在不断丰富,多值属性的关联规则在医学上的应用可能更广泛。
在病案信息库中记录有病人的病情和病人的个人资料,包括年龄、性别 、居住地、职业、生活情况等。在这样的数据库中进行关联规则挖掘,可找出哪些病并发的可能性较高,某些疾病与年龄、性别、居住地 、职业、生活习惯等的关系,比如从中可找出支持度为20%可信度为80%的这样一条规则:(年龄:35~45)∧(吸烟量:1包以上/天)肺病(80%,20%),它表示年龄在35~45间、吸烟量在1包以上/天的人中有80%患肺病的可能性,而且在数据库中有20%的记录支持这种情况。类似于这样的关联规则对医学研究、治疗和健康宣传都是非常有用的知识。
, 百拇医药
3 特征规则及其在医学上的应用
特征规则的挖掘就是对数据库中原始数据进行分析,获得它们所拥有的共同特征。挖掘特征规则的方法通常是根据属性列的熵的大小和概括层次树,对原始数据进行概括,合并相同元组,最后所得到的一个或几个“抽象宏记录”即为所挖掘的知识。在特征规则的发现中,概括的程度和发现的特征规则的多少由一个合适的阈值来控制,规则的数量被控制在阈值以内。阈值越大,发现的规则越多,但规则的概括程度越小。另外用可信度描述特征规则的普遍性。可信度定义为满足规则的记录在数据库中所占的比例[5,6]。
在医学研究中,对病案库进行特征规则的挖掘,可以找出患某种疾病的病号具有的自然特征,如前面所提到的年龄、工作性质等。这对医疗诊断和有针对性地预防某些疾病都是有益的指导。
4 分类规则及其在医学上的应用
在数据库中,有大量数据,对这些数据进行分析的一种情况就是根据某些标准对这些数据分类。在数据分类中,首先要选定一个模板数据集,它们能代表所要分类数据的类别,然后确定待分类数据集中每个数据的类别[5,6]。
, 百拇医药
在病案数据库中,如果已有一个各种疾病的模板数据集,其中的每个数据记录描述每种疾病的特征。将每个病号的病症数据与模板中的数据进行比较,确定它所属的类别,这实际上是一个医疗诊断过程。
5 结束语
数据挖掘在医学上的应用有它自身的优势,因为在医学上收集到的数据是真实可靠的,不受其它因素的影响,而且数据集的稳定性较强,这些对挖掘结果的维护、不断提高挖掘知识的质量都是非常有益的条件。
本文只是简单地介绍了数据挖掘在医学上应用的意向。由于数据挖掘是面向应用的,必须将医学领域的专业知识和挖掘人员的专业知识结合,收集大量的数据、反复实践才能形成一个真正实用的系统。但是医学肯定是数据挖掘技术应用的一个很好的领域,在近几年内一定会有医学上的数据挖掘系统投入使用,以帮助医学研究、疾病诊断和治疗。
参考文献
, http://www.100md.com
1 Srikant R,Agrawal R.Mining Sequential Patterns:Generalizations and Performance Improvement. Pro.5th Int'l conf. Extendign Database Technology.Avignon,France,1996,121~130
2 Agrawal R, Srikant R. Mining Sequential Patterns. Proc.11th int'l conf.Data Eng.Taipei,Taiwan,1995.3~14
3 Agrawal R, Imielinski T, Swami A.Mining Association Rules between Sets of Itemsets in Large Database.Proc. of 1993 ACM SIGMOD int'l conf. Management Data, Washington, D.C,1993.207~216
, http://www.100md.com
4 Agrawal R,Srilkant R.Fast Algorithms for Mining Association Rules in Large Databases.Proc.20th Int'l conf.VLDB,Santoago, Chile,1994.478~499
5 Che Ming-Syan, Han Jiawei,Yu PS.Data Mining:An Overview from a Database perspective.IEEE Transaction on Knowledge and Data Engineering,1996,8(6):867
6 刘伟宏,李晋晋,徐洁磐.通用数据库知识发现系统KNIGHT.计算机科学,1998(专刊):132
(1999-04-24 收稿), http://www.100md.com
单位:丁祥武 中南民族学院计算机科学系 武汉 430074 ;杨莹 湖北省钟祥市人民医院信息科
关键词:数据挖掘;序列模式;关联规则;特征规则;分类规则;医学应用
郧阳医学院学报990312中国图书资料分类法分类号 R-37
数据挖掘(Data Mining)即数据库中的知识发现KDD(knowledge discovery in databases)是从大型数据库中提取人们感兴趣的知识,这些知识是隐藏的、事先未知的、潜在有用的信息,挖掘的知识表现为概念、规则、规律、模式等形式[1]。数据挖掘为大型数据集的利用提供了有效工具。
数据挖掘起源于条码技术和大容量存储技术的使用,这样的环境使存储、处理大型的客户交易数据成为可能。随着计算机应用的日益普及,计算机在医学上的应用也越来越多。用计算机存储病案在医院已经比较普遍,而且各医院收集的数据又进一步汇总。如湖北省内县市级医院都用统一的医疗信息管理系统 SAS 来管理病案,这些数据又进一步汇总到省卫生厅,各省的病案数据进一步汇总。这样汇总的数据是相当庞大的,而且都是病人的真实数据,从这样的数据集中运用各种数据挖掘技术了解各种疾病之间的相互关系、各种疾病的发展规律,总结各种治疗方案的治疗效果,以及对疾病的诊断、治疗和医学研究都是非常有价值的。所以数据挖掘技术在医学上的应用是非常有潜力的。
, 百拇医药
数据挖掘发现的典型知识有序列模式、关联规则、特征规则、分类规则和聚类分析等。采用不同的技术可发现不同类型的知识。本文主要介绍挖掘序列模式、关联规则、特征规则和分类规则技术在医学上的应用。
1 序列模式及其在医学上的应用
给定一个交易数据库D,每条交易记录包含进行该交易的客户标识(Customer ID)、交易时间(Time)和在该交易中购买的项目(Items)。数据项集(Itemset)是数据项的非空集合,序列(Sequence)是数据项集的有序集。
设sa=A1,A2,…,Ak,sb=B1,B2,…,Bn是两个序列,如果存在整数1≤i1
Bi1,A2Bi2,…,AkBik,则称sa是sb的子序列,或称sb包含sa。例如<{3},{4,5},{8}>是<{3,8},{9},{4,5,6},{8}>的子序列,但<{3},{5}>与{3,5}>互不包含。, http://www.100md.com
在一个序列集合中,如果一个序列不包含在其它任何序列中,则称这个序列为最大序列。例如在{{3},{5},{3,5}}中,两个序列都是最大序列。
一个客户在一段时间内进行的所有交易可看作一个序列:s=〈itemset(T1),itemset(T2),…,itemset(Tn)〉,其中itemset(Ti)表示交易Ti采购的项目集,序列中的元素是按交易时间排序的,这样一个序列叫这个客户的客户序列。
如果一个序列s包含在一个客户的客户序列中,则称这个客户支持序列s。在一个交易数据库中,一个序列的支持度是支持这个序列的客户数占全部交易客户数的比例。
对一个交易数据库D,挖掘序列模式的任务就是在D中找出所有最大序列,这些序列满足用户指定的最小支持度,这样的一个序列叫一个序列模式。具有最小支持度的序列叫频繁序列。
, http://www.100md.com
在交易数据库D中挖掘序列模式是先将D转化为客户序列库Q,然后利用文[1,2]中介绍的方法,通过对Q多趟扫描找出各个长度的频繁序列,序列的长度指序列包含项的个数。例如对表1、2,如果用户指定的最小支持度为25%(有两位客户支持),则挖掘的序列模式有s1=<{30},{90}>和s2=<{30},{40,70}>。
表1 客户交易库D(已按客户号和交易时间排序) 客户号
交易时间
数据项
1
1999-02-20
30
1
, 百拇医药
199-02-25
90
2
1999-02-10
10,20
2
1999-02-15
30
2
1999-02-20
40,60,70
3
1999-02-25
, http://www.100md.com
30,50,70
4
1999-02-22
30
4
1999-02-28
40,70
4
1999-03-02
90
5
1999-02-10
90
, 百拇医药
如果在医院将就诊病人每次的病症输入到数据库中,组成一个庞大的数据库,对这个数据库进行一些必要的预处理,比如选取一类病情,然后利用挖掘序列模式的算法,挖掘满足支持度限制的序列模式,就可以发现一些病情的发展模式。
这种序列模式在医学上有许多作用,比如:
(1)确定某些疾病的发展模式,在治疗上可以根据病人的病史,预测病情发展趋势,从而有针对性地预防某些疾病的发生。
(2)给病人一些实际数据的说明,使病人高度重视某些疾病,防止病情进一步发展。
(3)如对某些治疗方案,收集治疗对象病情变化,每个病人的变化情况构成一个序列,在这样的序列库上挖掘序列模式,可以找出某些治疗方案的治疗效果。
(4)如果在数据库中记录时间信息,利用相应方法挖掘带时间约束的序列模式,可以进一步确定病情发展的时间情况或治疗效果的时间情况。
, 百拇医药
表2 表1对应的客户序列数据库Q 客户号
客户序列
1
<{30}{90}>
2
<{10,20},{30},{40,60,70}>
3
<{30,50,70}>
4
<{30},{40,70},{90}>
5
<{90}>
, 百拇医药
2 关联规则在医学上的应用
假设I={i1,i2,…,im}是项的集合。给定一个客户交易库D,每条交易T包含客户标识、交易时间和在该交易中购买的项目三个域。
如果对于I的一个子集X和D中的一条交易T有X
T(文中有时简单用T表示在交易T中购买的项目集),则说交易T包含项集X,或交易T支持项集X。一条关联规则是具有如下形式的蕴涵式X
Y,其中XI,YI,X∩Y=,同时有两个阀值c、s分别表示该规则的可信度和支持度,可信度c表示支持X∪Y的交易在支持X的交易中所占的比例,而支持度s是支持X∪Y的交易在整个交易库中所占的比例。, http://www.100md.com
在交易数据库D中挖掘关联规则的任务就是在D中找出所有满足用户指定最小支持度(min-support)和最小可信度(min-confidence)限制的关联规则。
一项集X的支持度是支持X的交易在整个交易库所占的比例。
在交易库D中挖掘关联规则可分解为下列两个子问题[3~4]:
(1)在D中找出所有的频繁项集,即支持不小于用户指定最小支持度的项集;
(2)应用频繁项集产生关联规则得到频繁项集之后,用它们确定关联规则是非常直接的,如果X是一个频繁项集,取X的非空子集α计算support(X)/support(α),如果其值≥c,则α
X-α就是满足最小支持度和最小可信度限制的关联规则,其中α叫规则的头部。进一步考察信趣度interest=(C-T)/max{C,T}可筛选出真正有趣的规则,T为支持该规则头部的交易数与支持规则的交易数的比值。, http://www.100md.com
找频繁集的过程[3~4]与前面找频繁序列的过程类似,也是通过多趟扫描交易库确定各个长度的频繁项集,项集的长度指的项集所包含项的个数。例如对表3所示的交易库,如果设s=60%(至少有两条交易支持),长度为2和3的频繁项集L2={{10,30},{20,30},{20,50},{30,50}},L3={{20,30,50}},如果设可信度c=70%,对频繁项集{10,30},10
30满足最小可信度限制,而3010的可信度为2/3=66.6%,不满足最小可信度限制。进一步如果设最小兴趣度=85%,由于1030的兴趣度只有(100%-66.6%)/100%=33.4%,因而不是有趣规则。表3 客户交易库客 户号, 百拇医药
交易时间
数据项
1
1999-03-18
10,30,40
2
1999-04-30
20,30,50
3
1999-05-15
10,20,30,50
4
, 百拇医药 1999-06-12
20,50
关联规则(Association rules)是最先提出的挖掘知识形式,也是数据挖掘的主要对象,主要应用于支持决策之中,只从Agrawal R[2]等在文中提出以来,就引起了数据库研究及其应用界的极大关注,其模型也在不断丰富,多值属性的关联规则在医学上的应用可能更广泛。
在病案信息库中记录有病人的病情和病人的个人资料,包括年龄、性别 、居住地、职业、生活情况等。在这样的数据库中进行关联规则挖掘,可找出哪些病并发的可能性较高,某些疾病与年龄、性别、居住地 、职业、生活习惯等的关系,比如从中可找出支持度为20%可信度为80%的这样一条规则:(年龄:35~45)∧(吸烟量:1包以上/天)
肺病(80%,20%),它表示年龄在35~45间、吸烟量在1包以上/天的人中有80%患肺病的可能性,而且在数据库中有20%的记录支持这种情况。类似于这样的关联规则对医学研究、治疗和健康宣传都是非常有用的知识。, 百拇医药
3 特征规则及其在医学上的应用
特征规则的挖掘就是对数据库中原始数据进行分析,获得它们所拥有的共同特征。挖掘特征规则的方法通常是根据属性列的熵的大小和概括层次树,对原始数据进行概括,合并相同元组,最后所得到的一个或几个“抽象宏记录”即为所挖掘的知识。在特征规则的发现中,概括的程度和发现的特征规则的多少由一个合适的阈值来控制,规则的数量被控制在阈值以内。阈值越大,发现的规则越多,但规则的概括程度越小。另外用可信度描述特征规则的普遍性。可信度定义为满足规则的记录在数据库中所占的比例[5,6]。
在医学研究中,对病案库进行特征规则的挖掘,可以找出患某种疾病的病号具有的自然特征,如前面所提到的年龄、工作性质等。这对医疗诊断和有针对性地预防某些疾病都是有益的指导。
4 分类规则及其在医学上的应用
在数据库中,有大量数据,对这些数据进行分析的一种情况就是根据某些标准对这些数据分类。在数据分类中,首先要选定一个模板数据集,它们能代表所要分类数据的类别,然后确定待分类数据集中每个数据的类别[5,6]。
, 百拇医药
在病案数据库中,如果已有一个各种疾病的模板数据集,其中的每个数据记录描述每种疾病的特征。将每个病号的病症数据与模板中的数据进行比较,确定它所属的类别,这实际上是一个医疗诊断过程。
5 结束语
数据挖掘在医学上的应用有它自身的优势,因为在医学上收集到的数据是真实可靠的,不受其它因素的影响,而且数据集的稳定性较强,这些对挖掘结果的维护、不断提高挖掘知识的质量都是非常有益的条件。
本文只是简单地介绍了数据挖掘在医学上应用的意向。由于数据挖掘是面向应用的,必须将医学领域的专业知识和挖掘人员的专业知识结合,收集大量的数据、反复实践才能形成一个真正实用的系统。但是医学肯定是数据挖掘技术应用的一个很好的领域,在近几年内一定会有医学上的数据挖掘系统投入使用,以帮助医学研究、疾病诊断和治疗。
参考文献
, http://www.100md.com
1 Srikant R,Agrawal R.Mining Sequential Patterns:Generalizations and Performance Improvement. Pro.5th Int'l conf. Extendign Database Technology.Avignon,France,1996,121~130
2 Agrawal R, Srikant R. Mining Sequential Patterns. Proc.11th int'l conf.Data Eng.Taipei,Taiwan,1995.3~14
3 Agrawal R, Imielinski T, Swami A.Mining Association Rules between Sets of Itemsets in Large Database.Proc. of 1993 ACM SIGMOD int'l conf. Management Data, Washington, D.C,1993.207~216
, http://www.100md.com
4 Agrawal R,Srilkant R.Fast Algorithms for Mining Association Rules in Large Databases.Proc.20th Int'l conf.VLDB,Santoago, Chile,1994.478~499
5 Che Ming-Syan, Han Jiawei,Yu PS.Data Mining:An Overview from a Database perspective.IEEE Transaction on Knowledge and Data Engineering,1996,8(6):867
6 刘伟宏,李晋晋,徐洁磐.通用数据库知识发现系统KNIGHT.计算机科学,1998(专刊):132
(1999-04-24 收稿), http://www.100md.com