基于TCGA 和GEO 数据库构建结肠癌预后模型
差异基因,因子,1材料与方法,2结果,3讨论
操利超,巴 颖,卢晓萍,张核子(深圳市核子基因科技有限公司,广东 深圳 518071)
结肠癌(colorectal cancer,CRC)是一种常见的恶性肿瘤,是世界上第二大致死原因[1]。尽管结肠癌的诊断和治疗已经取得了很大的进展,但结肠癌患者通常会出现复发和转移,导致5 年生存率显著下降[2]。因此,迫切需要改善结肠癌患者的诊断、治疗和预后。近些年来,分子诊断技术已广泛应用于肿瘤的治疗、预后领域[3-5]。生物信息学和机器学习技术已广泛应用于肿瘤诊断或预后分子标志物的识别,这种分子标志物类型多种多样,如microRNAs[6]、长链非编码RNA[7]、差异表达基因[8]、DNA 甲基化[9]等。其中,差异表达基因作为潜在的肿瘤诊断或预后标志物应用最为广泛。为得到广泛验证的结肠癌相关的差异表达基因,本文利用生物信息学方法,从多个数据集、不同的数据库中寻找共同的结肠癌相关的差异表达基因,并进一步利用机器学习的方法,从这些差异基因中挑选出结肠癌预后相关的预测因子,并建立预后风险评估模型。
1 材料与方法
1.1 数据下载和获取 通过GEO 数据库(https://www.ncbi.nlm.nih.gov/geo/)下载基因芯片表达数据集GSE44076、GSE28000 和GSE39582,每个参考数据集的正常和肿瘤样本情况见表1。TCGA 中mRNA表达数据集和对应的临床信息从UCSC Xena 平台(https://xenabrowser.net/datapages/)下载,选择队列为GDC TCGA Colon Cancer(COAD),样本信息见表2。
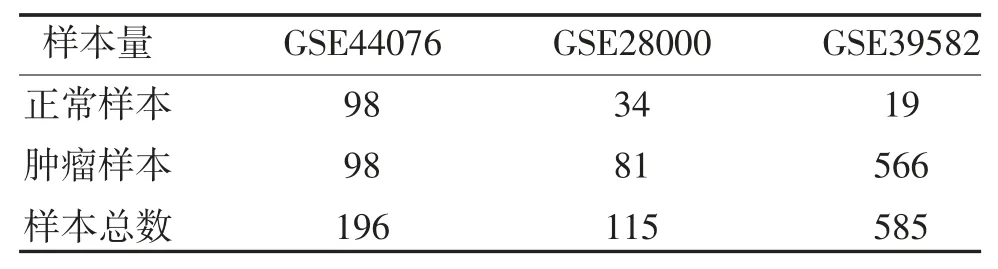
表1 3 个GEO 数据集的样本量情况

表2 TCGA 数据集的样本信息[n(%)]
1.2 差异基因分析和统计分析 利用R 包分别对3个GEO 数据集和TCGA 数据集进行差异基因分析 ......
您现在查看是摘要页,全文长 7633 字符。