内隐学习的人工神经网络模型(3)
 |
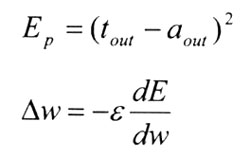 |
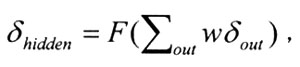 |
aWj为单元j的激活量。虽然,自动联系者模型没有可比对的反应模式,但是,上述算法的核心仍是用内部状态去匹配外部状态,尽量减少两者间的差异,因此,上述公式仍可看成delta法则*的变式。当然,除了使用delta法则来训练自动联系者外,也有研究者(例如,文献[14])使用类似模式联系者的Hebb法则训练该模型。和模式联系者一样,自动联系者也能习得不同的外部输入模式,并对此做出分类。可见,自动联系者能够很好地模拟人工语法学习任务学习和测试阶段的表面属性――无外部引导的分类学习任务。然而,它是否能模拟语法学习这一内部属性呢?
第三,人工语法学习的本质特征在于所获得的是有关语法的知识。虽然,如前所述,自动联系者获得的是一种无法外显的分布性表征的知识,但是,有意思的是这种表征似乎代表了某一类别的原型。而原型或许就好比语法的抽象表示方法。McClelland 和Rumelhart(1985)曾构建了一个由24个单元组成的自动联系者,将一些有关狗的信息输入这24个单元[7],其中前8个单元输入的是狗的名字信息,后16个单元输入的是狗的外貌信息,结果发现经过训练后,模型的权重矩阵呈现出特殊的构造,即前8个单元之间及前3个单元与后16个单元间的权重处于随机水平,而后16个单元间的权重却出现某种固定的模式,McClelland和Rumelhart认为这种固定的模式就是狗视觉表象的原型。虽然,无法从这种固定的权重模式中,看出典型的狗应该具有哪些特征,但是至少可以认为,如果两个单元间的连接权重比较大,那么当这两个单元同时被激活时,模型有可能将目标判断为狗。也就是说,原型所表征的是每个视觉特征间的联系。这就好比,人工语法学习中的语法知识,语法或许是由字母间的联系所表征的。所以,从这点意义上来,自动联系者习得的原型或许就是语法知识。
, http://www.100md.com
3.2 序列学习和简单循环网络
序列学习任务要求被试对一系列规则序列进行选择反应,其假设为:如果被试习得了序列间存在的固定规则,则他们可以依据前面呈现的序列来预测下一个项目是什么,成功的预测将会缩短被试的反应时[11]。序列学习和人工语法学习之间的本质区别在于:它是一项预测任务,而非分类任务,被试对某一项目的反应依赖于前面的项目。
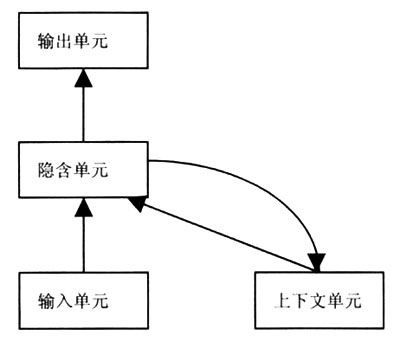
1990年,Elman开发了简单循环网络,专门用来模拟这类预测任务[9]。简单循环网络的目的是根据当前输入的项目来预测下一个项目,它的基本结构如图4所示,由4个加工单元层组成,它们分别是输入单元层、隐含单元层、上下文单元层和输出单元层。输入单元层用于表征当前输入的项目,输出单元层用于表征模型所预测的项目,上下文单元层用于表征在当前项目之前出现的项目序列,而隐含单元层负责在输入、输出和上下文单元层间的信息传递。简单循环网络的工作原理为:在接收第一
图4 简单循环网络的基本结构(资料来源:文献[16])
, http://www.100md.com
个项目时,输入层中的某些单元被激活,并将激活传递给隐含层中的单元,隐含层除了将激活进一步传递给输出层,由输出层预测第二个项目外,还将自己的激活水平复制于上下文层,当接收第二个项目时,隐含层除了收到来自输入层的激活外,还将收到来自上下文层的激活,因此,它向输出层传递的激活则包含了第一和第二两个项目的信息,依此类推,输出层所做出的预测是基于包含当前项目之内的所有项目的信息。当然,和其他许多人工神经网络模型一样,简单循环模型依据delta法则来调整权重的,即将模型给出的预测与真实出现的后续项目进行比较,来调整权重。不过,简单循环网络所使用的delta法则和自动联系者有两点差异:(1)权重调整是通过斜率递减法进行的,即寻求预测反应和真实项目之间误差方差的最小值,用公式表示为:
其中,tout为真实的正确输出,aout为模型的预测输出;(2)不同于自动联系者,简单循环网络是多层模型,当调整输出层单元和隐含层单元间的权重时,计算预测和真实项目间的误差方差是可以直接计算获得的,然而当要调整隐含层单元与输入层单元或上下文层单元间的权重时,由于不存在真实的正确反应,误差方差则无从计算,所以Rumelhart和McClelland(1986)提出可以用输出层单元的误差来估计隐含层单元的误差,即某一隐含单元的误差为所有与之连接的输出层单元的误差与它们之间权重乘积求和的函数[6]
, http://www.100md.com
然后,同样用斜率递减法求出权重的变化量,这种误差计算的法则和简单循环网络中原有的信息流方向正好相反,所以又被称为逆向推导。
简单循环网络能有效地模拟序列学习中的预测机制,因此,它刚提出不久,就被用于模拟内隐序列学习,用来研究序列学习的抽象性等问题[13,15,16]。
总之,针对不同的内隐学习任务,为了得到更佳的模拟效果,研究者往往倾向于选择不同人工神经网络模型加以模拟。然而,就像是任务之间的划分并不绝对一样(比如:Cleeremans等就曾将人工语法和序列学习结合在同一个任务中),神经网络模型和内隐学习任务间的匹配也并不绝对,比如:Boucher等(2003)就层用简单循环网络来模拟序列学习[17]。
4 小结
基于权重调整来学习正确反应的人工神经网络模型和内隐学习的两大本质特征间有着极优的匹配,人工神经网络模型在内隐学习领域的适用性毋庸置疑。在这样的背景下,出于深入探讨内隐学习的目的,研究者纷纷根据不同的内隐学习任务,选用不同的人工神经网络模型对之加以模拟[18]。到目前为止,针对两种较为普遍的内隐学习任务,也相应地出现了两种使用较为广泛的神经网络模型――自动联系者和简单循环网络。在实际研究中,合理地使用这两个模型,必将为内隐学习的理论和人工模拟提供更有力的证据。
, http://www.100md.com
参考文献
[1] Cleeremans A. Mechanisms of Implicit Learning: Connectionist Models of Sequence Processing. In: Jeffrey L E ed. Neural Network Modeling and Connectionism. London: MIT Press, 1993
[2] Dienes Z, Perner J. Implicit knowledge in people and connectionist networks. In: Underwood G.. Implicit cognition. Oxford: Oxford University Press, 1996
[3] McLeod P, Plunkett K, Rolls E T. Introduction to Connectionist Modelling of Cognitive Processes. Oxford: Oxford University Press, 1998
[4] Milner P. A Brief History of the Hebbian Learning Rule. Canadian Psychology, 2003, 44(1): 5~9
[5] Rosenblatt F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychological Reviews, 1958, 65: 386~408
[ 上 页 ] [ 下 页 ], 百拇医药(郭秀艳 朱 磊 魏知超)